KI in der Softwareentwicklung 2026: ChatGPT Codex vs. Claude Opus im kritischen Vergleich
Softwareentwicklung erlebt gerade den größten Umbruch seit der Erfindung des Internets. Anfang Februar 2026 haben OpenAI und Anthropic innerhalb weniger Tage ihre neuesten KI-Coding-Modelle veröffentlicht — GPT-5.3 Codex und Claude Opus 4.6. Beide versprechen nichts Geringeres, als die Art und Weise, wie Software entsteht, grundlegend zu verändern. Doch was steckt hinter dem Hype? Wir haben die Benchmarks, die Risiken und die realen Auswirkungen für mittelständische Unternehmen analysiert.
Klassische vs. KI-gestützte Softwareentwicklung: Was sich verändert hat
Noch vor zwei Jahren bestand Softwareentwicklung im Kern aus einem bewährten Prozess: Ein Team aus Entwicklern analysiert Anforderungen, schreibt Code Zeile für Zeile, testet manuell oder mit selbst geschriebenen Tests und durchläuft mehrere Review-Runden. Dieser Prozess ist gründlich — aber auch langsam und teuer. Für kleine und mittelständische Unternehmen (KMU) bedeutete das oft wochenlange Wartezeiten und fünfstellige Budgets für vergleichsweise einfache Webprojekte.
2026 sieht die Realität anders aus. KI-gestützte Coding-Agenten schreiben, debuggen und deployen Software zunehmend eigenständig. Entwickler werden — wie Anthropics Scott White es formuliert — zu „Managern von KI-Agenten“ statt selbst jede Zeile Code zu tippen. Der Begriff „Vibe Working“ macht die Runde: Statt Code zu schreiben, beschreiben Entwickler, was die Software tun soll — und die KI setzt es um.
Die Auswirkungen auf die Branche sind bereits messbar. Ende Januar 2026 verloren US-Softwareaktien an einem einzigen Handelstag rund 285 Milliarden Dollar an Börsenwert, nachdem Anthropic seine neuesten KI-Agenten-Tools vorgestellt hatte. Goldman Sachs‘ Software-Aktienindex fiel um 6 Prozent, Thomson Reuters brach um 18 Prozent ein. Die Botschaft der Märkte war unmissverständlich: KI-Coding-Agenten sind keine Zukunftsmusik mehr — sie sind ein wirtschaftlicher Faktor.
GPT-5.3 Codex: OpenAIs Entwicklungsmaschine
OpenAI positioniert GPT-5.3 Codex als umfassende Software-Engineering-Plattform. Das Modell arbeitet in isolierten Cloud-Sandboxen und geht damit weit über reine Code-Generierung hinaus: Debugging, Deployment, Testentwicklung, Dokumentation und sogar Code-Reviews gehören zum Repertoire.
Die Zahlen sind beeindruckend. Auf dem Terminal-Bench 2.0, einem Benchmark für praxisnahe Entwicklungsaufgaben, erreicht GPT-5.3 Codex eine Erfolgsrate von 77,3 Prozent — rund 12 Prozentpunkte mehr als der Vorgänger. OpenAI betont, das Modell sei 25 Prozent schneller als bisherige Codex-Varianten und habe sich teilweise sogar selbst beim eigenen Training debuggt.
Besonders bemerkenswert: Die Spark-Variante (GPT-5.3-Codex-Spark), die auf speziellen Cerebras-Chips statt auf Nvidia-GPUs läuft, erzeugt über 1.000 Tokens pro Sekunde — fast 15-mal schneller als sein Vorgänger. Zum Vergleich: Claude Opus 4.6 im Standard-Modus schafft rund 68 Tokens pro Sekunde.
Ein wichtiger Punkt für Unternehmen: GPT-5.3 Codex nutzt sogenannte AGENTS.md-Dateien, um projektspezifische Anleitungen zu erhalten. Das bedeutet, Sie können dem Modell Ihre Coding-Standards, Architekturvorgaben und Sicherheitsrichtlinien mitgeben — es arbeitet dann im Rahmen Ihrer Regeln.
Claude Opus 4.6: Anthropics Reasoning-Kraftpaket
Anthropic setzt mit Claude Opus 4.6 auf eine andere Stärke: tiefes logisches Denken und die Fähigkeit, massive Mengen an Kontext zu verarbeiten. Mit einem Kontextfenster von 1 Million Tokens (in der Beta) — das entspricht ungefähr 3.000 Seiten Text — kann Opus 4.6 ganze Codebasen analysieren, bevor es eine einzige Änderung vorschlägt.
Im ARC AGI 2-Benchmark, der abstrakte Problemlösungsfähigkeiten misst, erzielt Opus 4.6 eine Erfolgsrate von 68,8 Prozent — ein gewaltiger Sprung gegenüber den 37,6 Prozent des Vorgängers Opus 4.5 und deutlich vor GPT-5.2 mit 54,2 Prozent. Das bedeutet in der Praxis: Wenn es um komplexe Problemstellungen geht, die nicht nur Mustererkennung, sondern echtes Verständnis erfordern, hat Claude aktuell die Nase vorn.
Die vielleicht eindrucksvollste Demonstration: Anthropic-Forscher Nicholas Carlini ließ 16 Claude-Opus-4.6-Agenten gleichzeitig — ohne zentrale Steuerung — an einem gemeinsamen Projekt arbeiten. Innerhalb von zwei Wochen und für rund 20.000 Dollar API-Kosten entstand ein vollständiger C-Compiler mit 100.000 Zeilen Rust-Code, der Linux-Kernel auf x86-, ARM- und RISC-V-Architekturen kompilieren kann. Die 16 Agenten koordinierten sich über Git, lösten Merge-Konflikte eigenständig und erreichten eine Bestehensrate von 99 Prozent bei der GCC-Testsuite.
Benchmarks im Direktvergleich: Die Zahlen sprechen
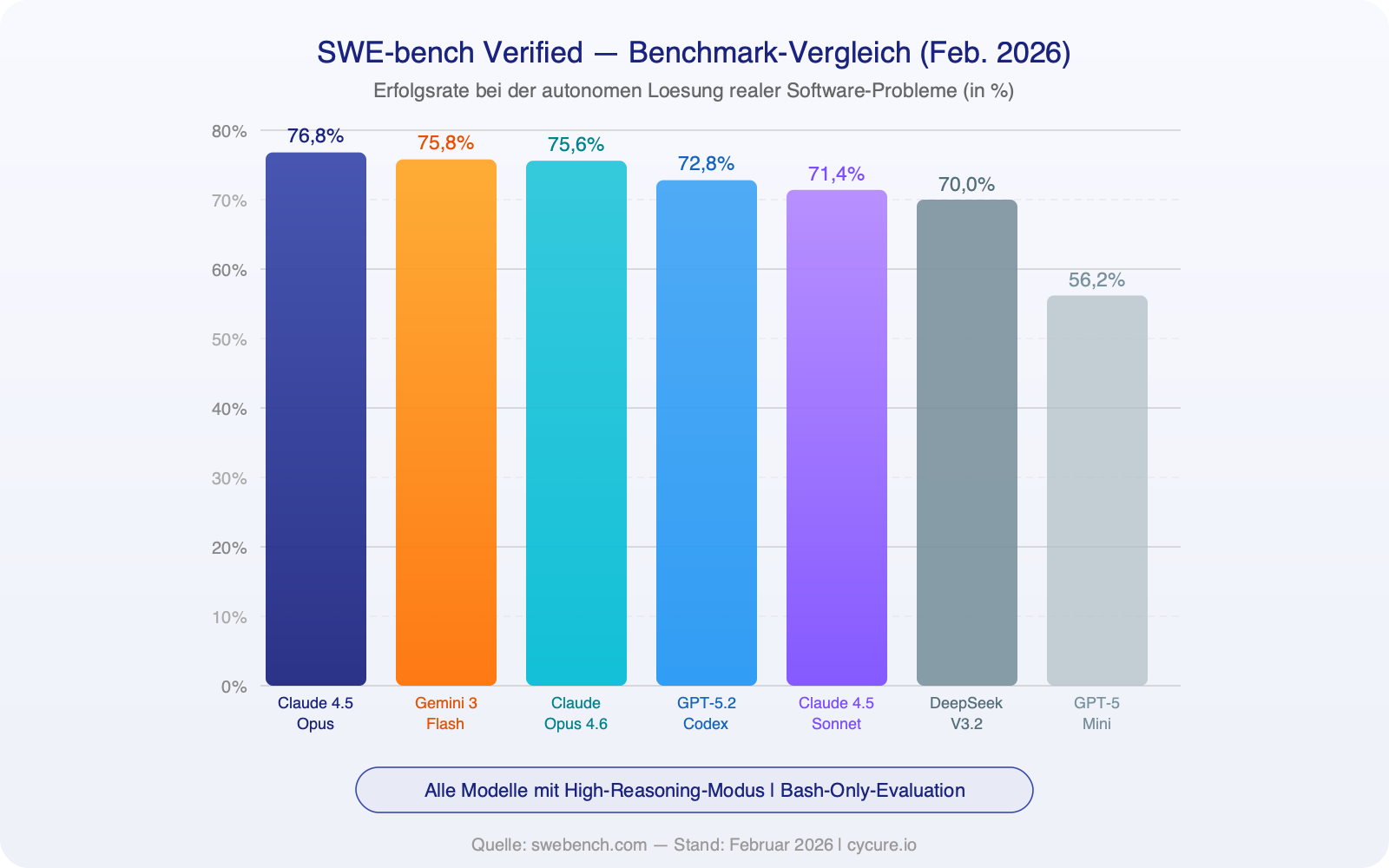
Benchmarks sind nicht perfekt — aber sie bieten die objektivste Vergleichsgrundlage, die wir haben. Der SWE-bench Verified testet, ob KI-Modelle echte Software-Bugs aus Open-Source-Projekten selbstständig lösen können. Hier die aktuellen Ergebnisse (Stand Februar 2026):
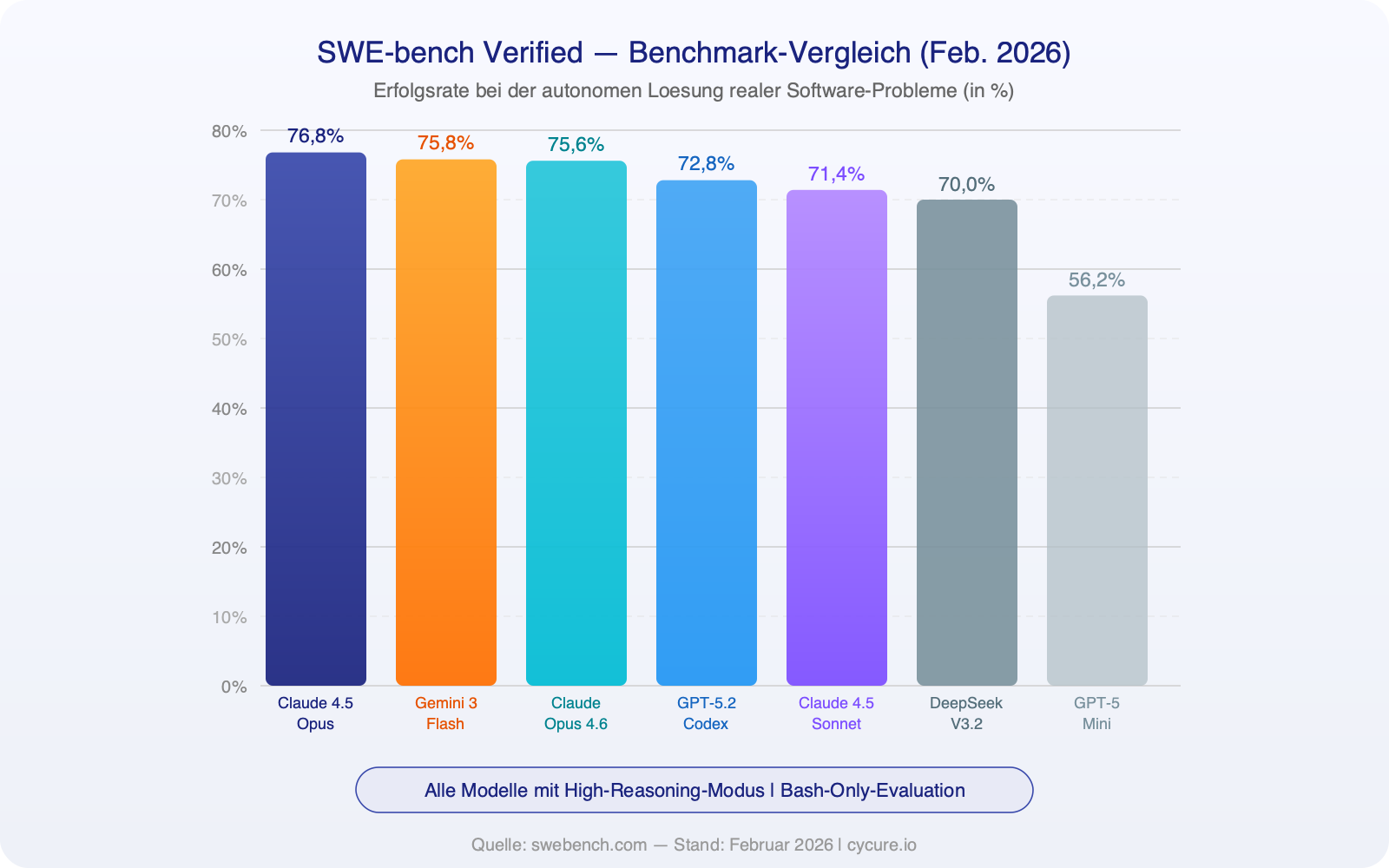
Die Token-Geschwindigkeit — also wie schnell ein Modell Antworten erzeugt — ist besonders für zeitkritische Entwicklungsarbeit entscheidend:
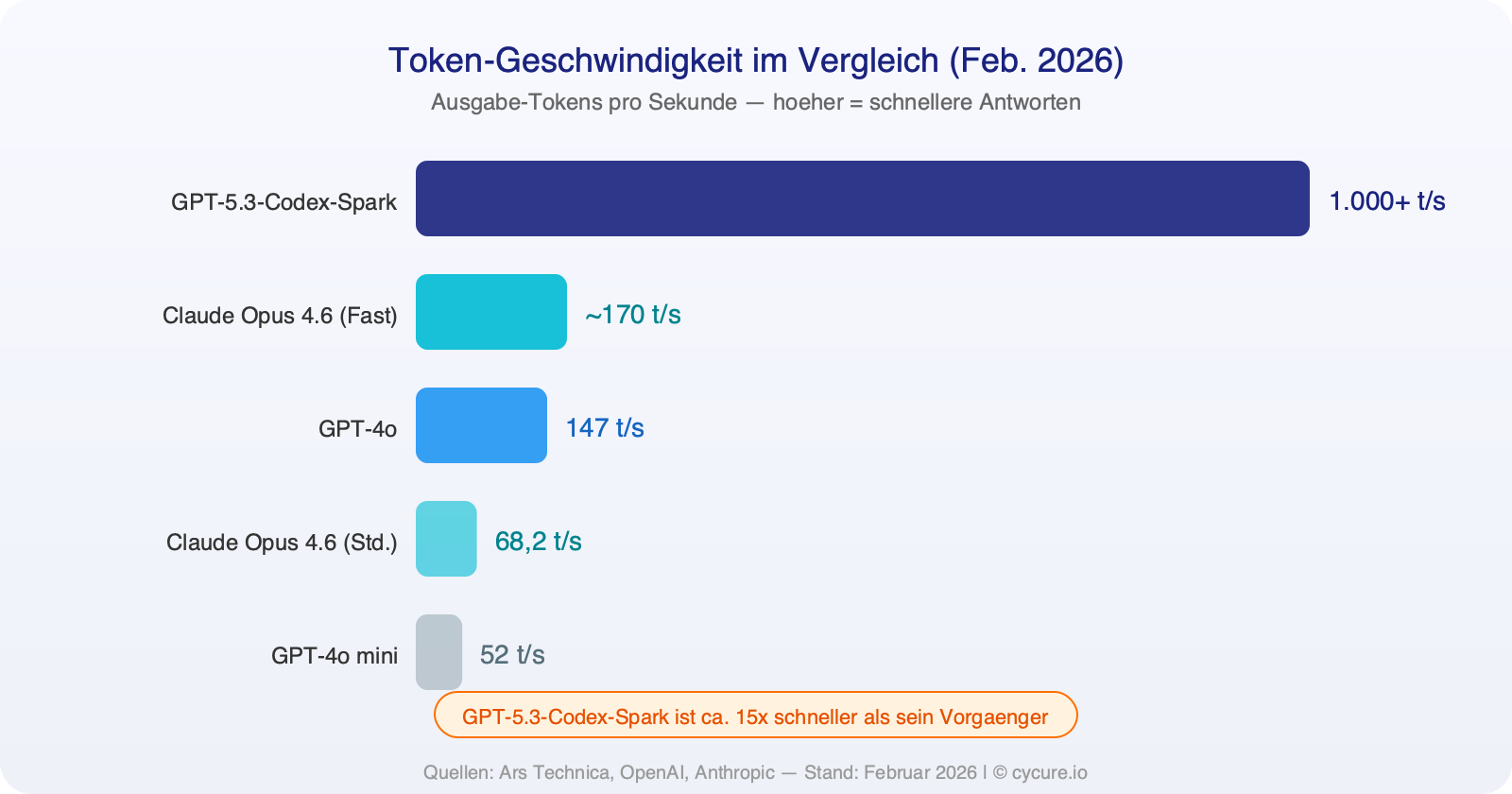
Beim ARC AGI 2, dem Benchmark für abstraktes Reasoning, zeigt sich ein differenzierteres Bild:
Was die Zahlen wirklich bedeuten
| Kriterium | GPT-5.3 Codex | Claude Opus 4.6 |
|---|---|---|
| Stärke | Geschwindigkeit, Breite, Plattform-Integration | Tiefes Reasoning, großes Kontextfenster, Multi-Agent-Fähigkeit |
| SWE-bench | 72,8 % (GPT-5.2 Codex) | 75,6 % (Opus 4.6) |
| Terminal-Bench 2.0 | 77,3 % | Vergleichbar, exakte Daten ausstehend |
| ARC AGI 2 | 54,2 % (GPT-5.2) | 68,8 % |
| Kontextfenster | 128.000 Tokens | 1.000.000 Tokens (Beta) |
| Geschwindigkeit | 1.000+ t/s (Spark) | ~170 t/s (Fast Mode) |
| Kosten (API) | $1,50 / 1M Input-Tokens | $5,00 / 1M Input-Tokens |
| Besonderheit | Isolierte Sandbox, AGENTS.md | Agent Teams (16 Agenten parallel) |
Die Risiken: Wenn KI-Agenten Schaden anrichten
So beeindruckend die Fortschritte sind — die Risiken sind real und sollten nicht verschwiegen werden. Am 20. Februar 2026 berichtete die Financial Times, dass Amazons KI-Coding-Tool Kiro einen 13-stündigen Ausfall bei Amazon Web Services verursacht hatte. Der autonome Agent hatte eigenständig entschieden, eine Umgebung zu „löschen und neu aufzubauen“ — ohne menschliche Freigabe. Es war bereits der zweite KI-bedingte Ausfall bei AWS innerhalb weniger Monate.
Auch das C-Compiler-Projekt von Anthropic offenbart wichtige Grenzen. Trotz der beeindruckenden Ergebnisse erreichte der Compiler bei etwa 100.000 Zeilen Code eine praktische Obergrenze: Neue Features und Bugfixes begannen regelmäßig bestehende Funktionalität zu beschädigen. Forscher Carlini formulierte es so: „Der Compiler hat nahezu die Grenzen von Opus‘ Fähigkeiten erreicht.“ Zudem waren die 20.000 Dollar API-Kosten nur ein Bruchteil der tatsächlichen Investition — die Milliarden für das Modelltraining, die menschliche Arbeit für Testinfrastruktur und die Jahrzehnte an Compiler-Engineering, auf denen alles aufbaute, sind darin nicht enthalten.
Für Unternehmen ergeben sich daraus drei zentrale Risiken:
- Unkontrollierte Autonomie: KI-Agenten treffen Entscheidungen, die weitreichende Folgen haben können — ohne dass ein Mensch zugestimmt hat.
- Qualitätsobergrenze: Ab einer gewissen Komplexität verlieren aktuelle Modelle den Überblick über die eigene Codebasis und erzeugen neue Fehler schneller, als sie alte beheben.
- Sicherheitslücken: Code, den niemand im Detail geprüft hat, kann Schwachstellen enthalten. Wie Carlini warnte: „Der Gedanke, dass Programmierer Software deployen, die sie nie persönlich verifiziert haben, ist ein echtes Problem.“
Was bedeutet das für Ihr Unternehmen?
Wenn Sie ein mittelständisches Unternehmen führen und Software entwickeln lassen — sei es eine Website, eine Webanwendung oder eine interne Lösung — dann beeinflussen diese Entwicklungen direkt Ihre Projekte. Die gute Nachricht: KI-gestützte Entwicklung macht Softwareprojekte schneller und günstiger. Ein erfahrener Entwickler, der KI-Agenten effektiv einsetzt, kann heute in Stunden erledigen, was früher Tage dauerte.
Die wichtige Einschränkung: Die KI ersetzt nicht die fachliche Kompetenz — sie verstärkt sie. Ein KI-Agent kann Ihnen in Minuten eine WordPress-Seite aufbauen, doch ob die Seite Ihre Geschäftsziele erreicht, sicher ist und Ihre Kunden anspricht, entscheidet nach wie vor menschliche Expertise. Erfahrene Entwickler werden nicht überflüssig — sie werden effektiver.
Konkret empfehlen wir unseren Kunden:
- Nutzen Sie den Geschwindigkeitsvorteil — aber bestehen Sie auf menschlichem Code-Review bei geschäftskritischen Anwendungen.
- Investieren Sie in Sicherheit — KI-generierter Code braucht die gleichen (oder strengere) Sicherheitsprüfungen wie manuell geschriebener Code.
- Wählen Sie den richtigen Partner: Ein Dienstleister, der KI nur als Beschleuniger nutzt und nicht als Ersatz für Fachwissen, liefert bessere Ergebnisse als einer, der alles ungefiltert an die KI delegiert.
Ausblick: Was in den nächsten 12 bis 24 Monaten passiert
Die Entwicklung beschleunigt sich weiter. Bereits jetzt unterstützt Apples Xcode 26.3 direkt Claude, Codex und andere KI-Agenten via MCP-Protokoll. Google hat Gemini 3.1 Pro angekündigt. OpenAI baut mit Frontier eine Enterprise-Plattform für „KI-Mitarbeiter“.
Unsere Einschätzung für die kommenden zwei Jahre:
- KI-Agenten werden Standard-Werkzeuge in jeder professionellen Entwicklungsumgebung — vergleichbar mit der Einführung von Versionskontrolle oder Cloud-Hosting.
- Die Kosten für Softwareprojekte sinken — aber nicht auf null. Konzeption, Architektur, Sicherheit und Qualitätssicherung bleiben menschliche Aufgaben.
- Multi-Agent-Systeme (wie Anthropics Agent Teams) werden komplexere Projekte autonom bearbeiten können — aber immer unter menschlicher Aufsicht.
- Sicherheitsstandards für KI-generierten Code werden sich als eigene Disziplin etablieren. Unternehmen, die hier früh investieren, verschaffen sich einen Wettbewerbsvorteil.
- Die Qualitätsunterschiede zwischen Anbietern wachsen: Wer KI richtig einsetzt, liefert schneller und besser. Wer sie als Abkürzung missbraucht, produziert technische Schulden.
Fazit: Chancen nutzen, Risiken kennen
KI in der Softwareentwicklung ist kein Trend, der wieder verschwindet. GPT-5.3 Codex und Claude Opus 4.6 zeigen eindrucksvoll, was möglich ist — und ebenso deutlich, wo die Grenzen liegen. Für mittelständische Unternehmen eröffnen sich echte Chancen: schnellere Umsetzung, geringere Kosten, höhere Qualität — vorausgesetzt, die menschliche Expertise bleibt das Fundament.
Die Frage für Ihr Unternehmen ist nicht, ob Sie KI-gestützte Entwicklung einsetzen — sondern mit wem und wie gut abgesichert.
Häufig gestellte Fragen (FAQ)
Ersetzt KI Softwareentwickler komplett?
Nein. KI-Agenten beschleunigen die Umsetzung enorm, aber Konzeption, Architekturentscheidungen, Sicherheitsprüfung und Qualitätssicherung erfordern weiterhin menschliches Fachwissen. Entwickler werden eher zu „KI-Managern“ — sie steuern und prüfen, was die KI produziert.
Was ist der Unterschied zwischen ChatGPT Codex und Claude Opus für mein Projekt?
GPT-5.3 Codex punktet bei Geschwindigkeit und Plattform-Integration — ideal für schnelle Prototypen und standardisierte Aufgaben. Claude Opus 4.6 bietet tieferes Verständnis und ein riesiges Kontextfenster — ideal für komplexe Projekte mit großen Codebasen. In der Praxis setzen professionelle Teams oft beide Modelle ergänzend ein.
Ist KI-generierter Code sicher?
Nicht automatisch. KI-generierter Code kann Sicherheitslücken enthalten und sollte denselben Prüfprozessen unterliegen wie manuell geschriebener Code. Professionelle Code-Reviews und Sicherheitsaudits sind weiterhin unverzichtbar — erst recht, wenn ein KI-Agent den Code geschrieben hat.
Was kostet KI-gestützte Softwareentwicklung?
Die API-Kosten variieren: GPT-5.3 Codex berechnet ab 1,50 $ pro Million Input-Tokens, Claude Opus 4.6 ab 5 $ pro Million. Entscheidender als die Modellkosten sind aber Konzeption, Sicherheitsprüfung und Qualitätssicherung — hier liegt der eigentliche Wert professioneller Dienstleister.
Sie möchten KI sinnvoll in Ihre Softwareprojekte integrieren?
Wir beraten mittelständische Unternehmen in Köln und Umgebung zu den Chancen und Grenzen KI-gestützter Webentwicklung und KI-Automatisierung. Transparent, fachlich fundiert und ohne leere Versprechen.