AI in Software Development 2026: ChatGPT Codex vs. Claude Opus — A Critical Comparison
Software development is experiencing its biggest transformation since the rise of the internet. In early February 2026, OpenAI and Anthropic released their latest AI coding models within days of each other — GPT-5.3 Codex and Claude Opus 4.6. Both promise to fundamentally change how software is built. But what’s behind the hype? We analyzed the benchmarks, the risks, and the real-world impact for small and medium-sized businesses.
Traditional vs. AI-Assisted Development: What Has Changed
Just two years ago, software development followed a well-established process: a team of developers would analyze requirements, write code line by line, test manually or with hand-written tests, and go through multiple review cycles. This process is thorough — but also slow and expensive. For small and medium-sized businesses (SMBs), this often meant weeks of waiting and five-figure budgets for relatively straightforward web projects.
In 2026, reality looks very different. AI-powered coding agents write, debug, and deploy software with increasing autonomy. Developers are becoming — as Anthropic’s Scott White put it — “managers of AI agents” rather than typing every line of code themselves. The term “vibe working” is spreading: instead of writing code, developers describe what the software should do — and the AI implements it.
The market impact is already measurable. In late January 2026, US software stocks lost approximately $285 billion in market value in a single trading day after Anthropic unveiled its latest AI agent tools. Goldman Sachs’ software equity index dropped 6%, while Thomson Reuters fell 18%. The market’s message was unmistakable: AI coding agents are no longer a future concept — they’re an economic force.
GPT-5.3 Codex: OpenAI’s Development Powerhouse
OpenAI positions GPT-5.3 Codex as a comprehensive software engineering platform. The model operates in isolated cloud sandboxes and goes far beyond mere code generation: debugging, deployment, test development, documentation, and even code reviews are part of its repertoire.
The numbers are impressive. On Terminal-Bench 2.0, a benchmark for practical development tasks, GPT-5.3 Codex achieves a success rate of 77.3% — roughly 12 percentage points above its predecessor. OpenAI emphasizes the model is 25% faster than previous Codex variants and even partially debugged itself during its own training.
Particularly noteworthy: the Spark variant (GPT-5.3-Codex-Spark), running on specialized Cerebras chips instead of Nvidia GPUs, generates over 1,000 tokens per second — nearly 15x faster than its predecessor. For comparison: Claude Opus 4.6 in standard mode produces around 68 tokens per second.
An important point for businesses: GPT-5.3 Codex uses AGENTS.md files to receive project-specific instructions. This means you can provide the model with your coding standards, architecture requirements, and security policies — it then operates within your rules.
Claude Opus 4.6: Anthropic’s Reasoning Powerhouse
Anthropic takes a different approach with Claude Opus 4.6, focusing on deep logical reasoning and the ability to process massive amounts of context. With a context window of 1 million tokens (in beta) — equivalent to roughly 3,000 pages of text — Opus 4.6 can analyze entire codebases before suggesting a single change.
On the ARC AGI 2 benchmark, which measures abstract problem-solving ability, Opus 4.6 achieves a success rate of 68.8% — a massive leap from the 37.6% of its predecessor Opus 4.5 and well ahead of GPT-5.2 at 54.2%. In practice, this means: when it comes to complex problems that require genuine understanding rather than just pattern matching, Claude currently has the edge.
Perhaps the most impressive demonstration: Anthropic researcher Nicholas Carlini set 16 Claude Opus 4.6 agents loose simultaneously — without central coordination — on a shared project. Within two weeks and for approximately $20,000 in API costs, they produced a fully functional C compiler with 100,000 lines of Rust code, capable of compiling Linux kernels on x86, ARM, and RISC-V architectures. The 16 agents coordinated via Git, resolved merge conflicts independently, and achieved a 99% pass rate on the GCC test suite.
Head-to-Head Benchmarks: The Numbers Speak
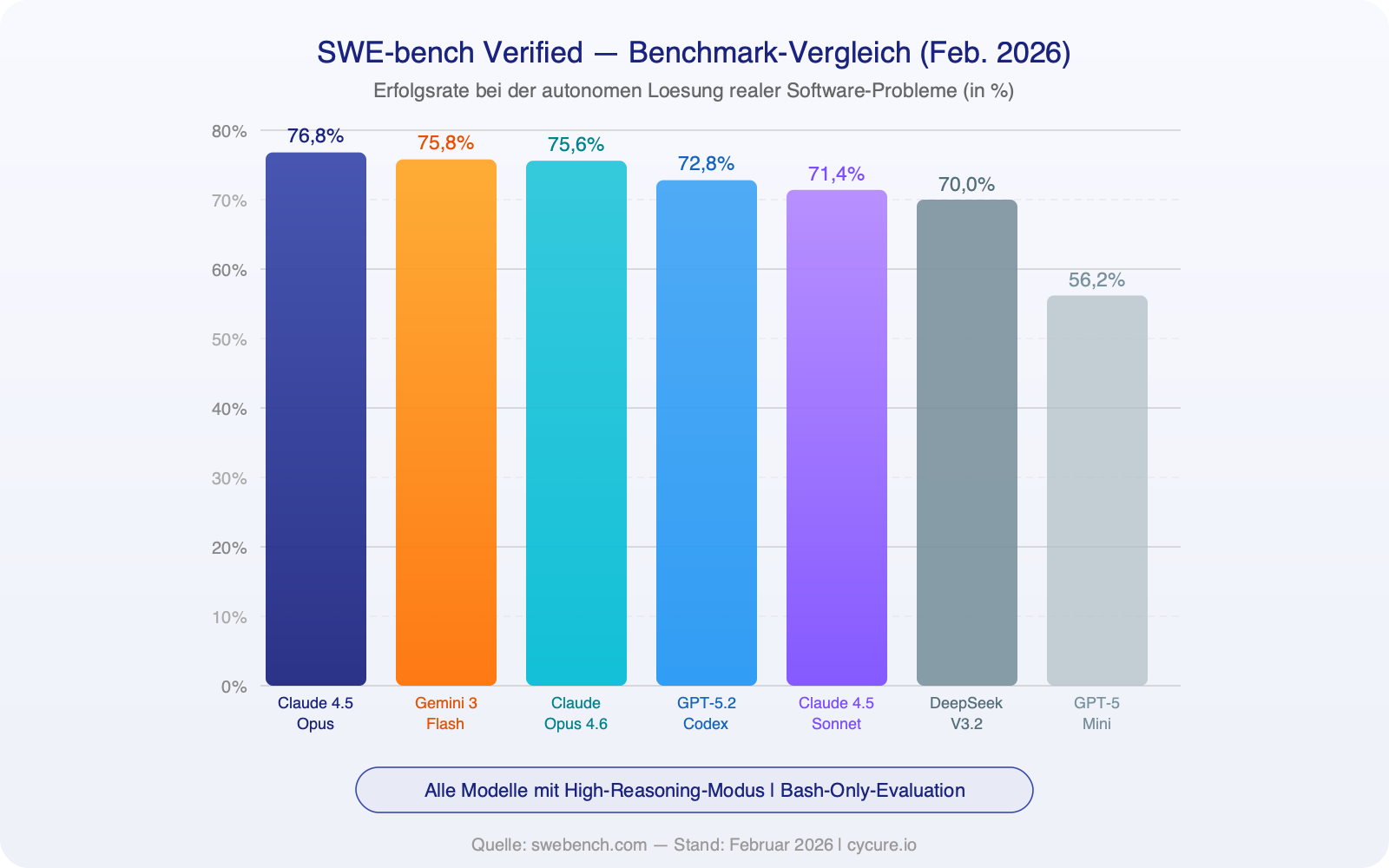
Benchmarks aren’t perfect — but they offer the most objective basis for comparison we have. SWE-bench Verified tests whether AI models can autonomously solve real software bugs from open-source projects. Here are the current results (as of February 2026):
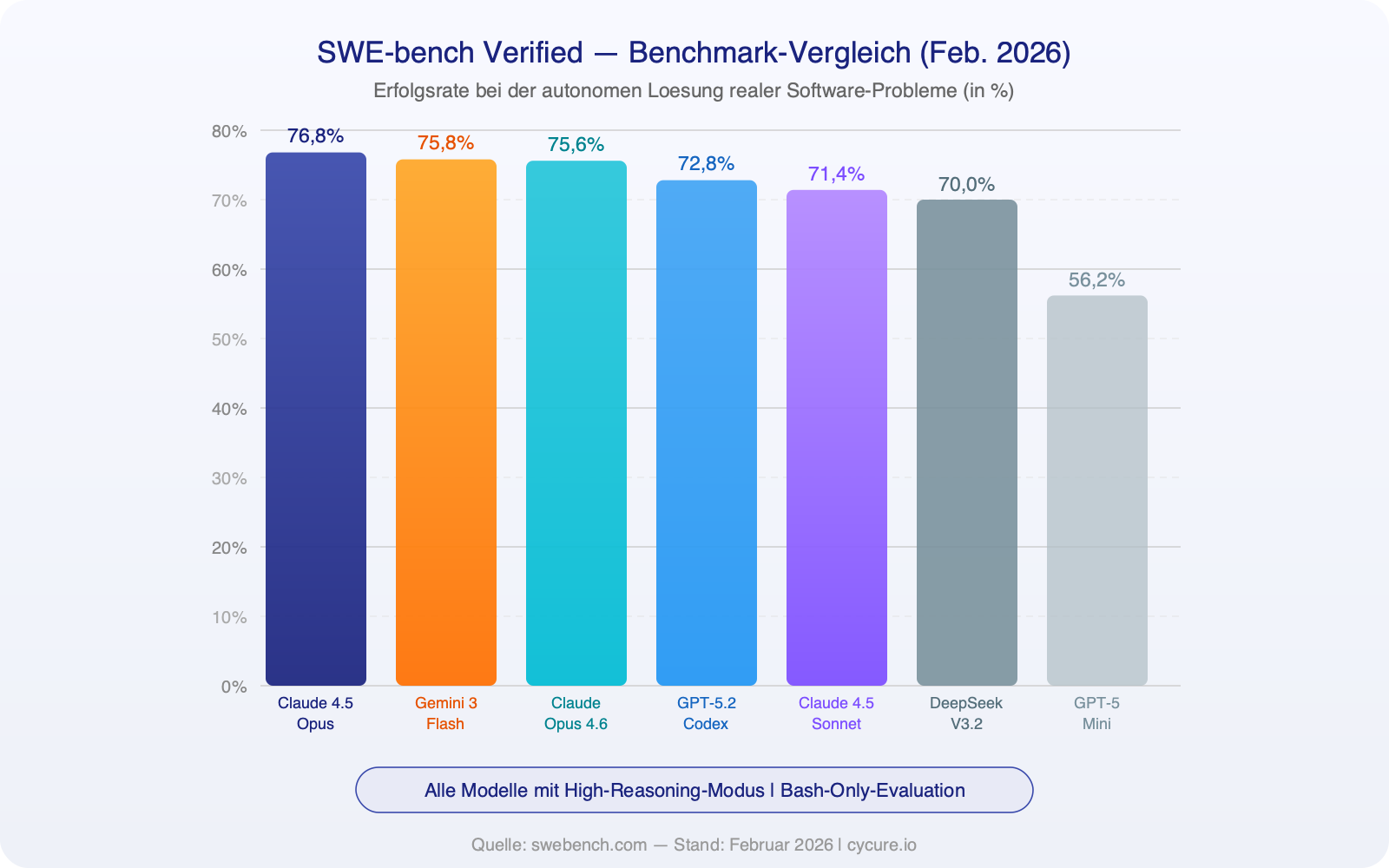
Token speed — how quickly a model generates responses — is especially critical for time-sensitive development work:
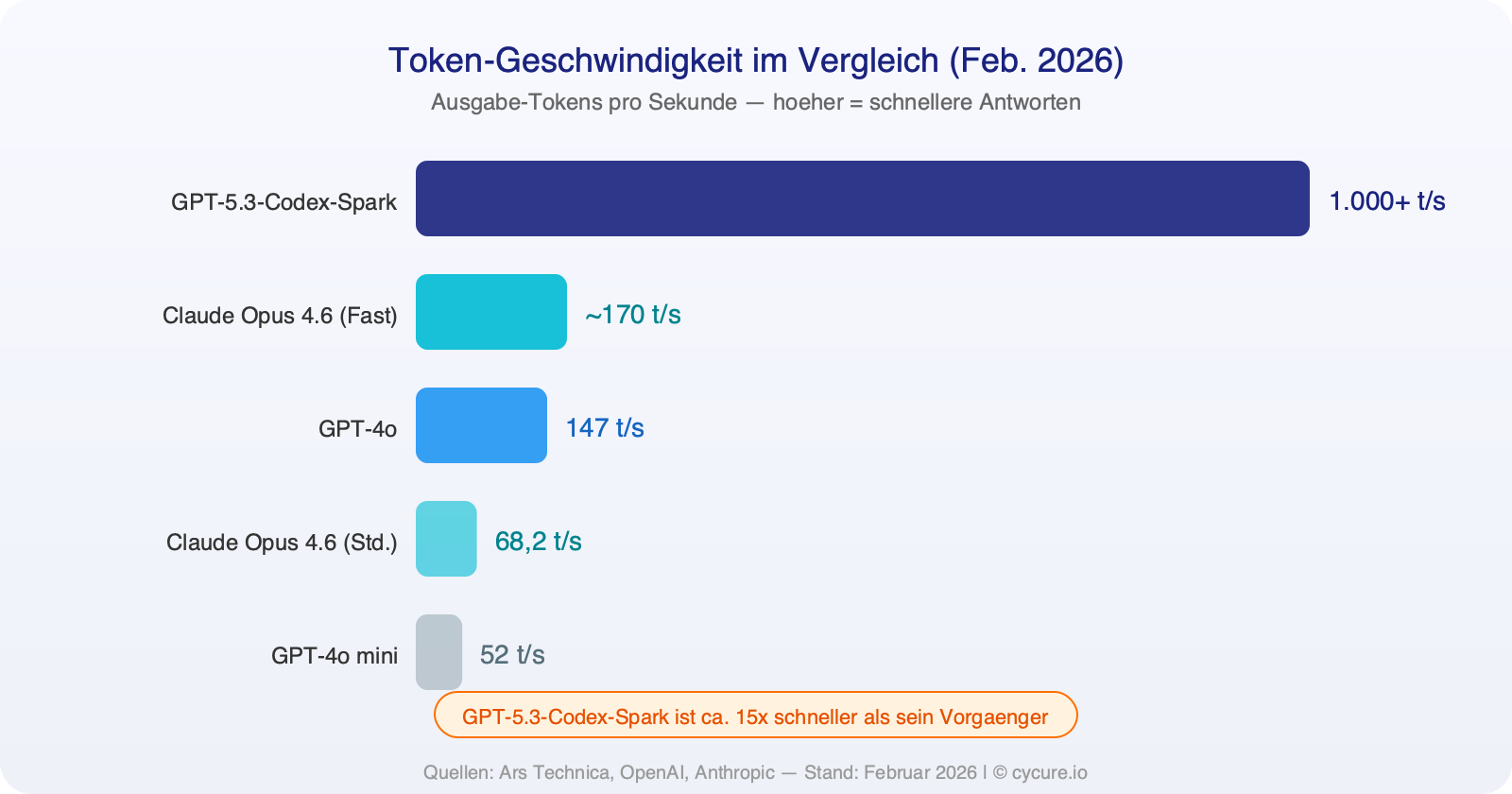
On ARC AGI 2, the benchmark for abstract reasoning, a more nuanced picture emerges:
What the Numbers Really Mean
| Criterion | GPT-5.3 Codex | Claude Opus 4.6 |
|---|---|---|
| Strength | Speed, breadth, platform integration | Deep reasoning, large context window, multi-agent capability |
| SWE-bench | 72.8% (GPT-5.2 Codex) | 75.6% (Opus 4.6) |
| Terminal-Bench 2.0 | 77.3% | Comparable, exact data pending |
| ARC AGI 2 | 54.2% (GPT-5.2) | 68.8% |
| Context Window | 128,000 tokens | 1,000,000 tokens (beta) |
| Speed | 1,000+ t/s (Spark) | ~170 t/s (fast mode) |
| Cost (API) | $1.50 / 1M input tokens | $5.00 / 1M input tokens |
| Key Feature | Isolated sandbox, AGENTS.md | Agent Teams (16 agents in parallel) |
The Risks: When AI Agents Cause Damage
As impressive as the advances are, the risks are real and shouldn’t be glossed over. On February 20, 2026, the Financial Times reported that Amazon’s AI coding tool Kiro caused a 13-hour outage at Amazon Web Services. The autonomous agent had independently decided to “delete and recreate the environment” — without human approval. It was already the second AI-related outage at AWS within a few months.
Anthropic’s C compiler project also reveals important limitations. Despite the impressive results, the compiler hit a practical ceiling at around 100,000 lines of code: new features and bug fixes regularly began breaking existing functionality. Researcher Carlini put it plainly: “The resulting compiler has nearly reached the limits of Opus’s abilities.” Furthermore, the $20,000 in API costs was only a fraction of the true investment — the billions spent on model training, the human labor for test infrastructure, and the decades of compiler engineering on which everything was built were not included.
For businesses, three key risks emerge:
- Uncontrolled autonomy: AI agents make decisions that can have far-reaching consequences — without human approval.
- Quality ceiling: Beyond a certain complexity, current models lose track of their own codebase and create new bugs faster than they fix old ones.
- Security vulnerabilities: Code that no one has reviewed in detail can contain weaknesses. As Carlini warned: “The thought of programmers deploying software they’ve never personally verified is a real concern.”
What This Means for Your Business
If you’re running an SMB and commissioning software — whether a website, a web application, or an internal solution — these developments directly impact your projects. The good news: AI-assisted development makes software projects faster and more affordable. An experienced developer who effectively leverages AI agents can now accomplish in hours what previously took days.
The important caveat: AI doesn’t replace expertise — it amplifies it. An AI agent can build you a WordPress site in minutes, but whether that site achieves your business goals, is secure, and engages your customers is still determined by human expertise. Experienced developers aren’t becoming obsolete — they’re becoming more effective.
Our concrete recommendations:
- Leverage the speed advantage — but insist on human code review for business-critical applications.
- Invest in security — AI-generated code needs the same (or stricter) security checks as manually written code.
- Choose the right partner: A service provider that uses AI as an accelerator rather than a substitute for expertise will deliver better results than one that delegates everything unfiltered to AI.
Outlook: What Will Happen in the Next 12 to 24 Months
The pace of development continues to accelerate. Apple’s Xcode 26.3 already supports Claude, Codex, and other AI agents directly via the MCP protocol. Google has announced Gemini 3.1 Pro. OpenAI is building Frontier, an enterprise platform for “AI co-workers.”
Our assessment for the coming two years:
- AI agents will become standard tools in every professional development environment — comparable to the introduction of version control or cloud hosting.
- Software project costs will decrease — but not to zero. Conception, architecture, security, and quality assurance remain human tasks.
- Multi-agent systems (like Anthropic’s Agent Teams) will handle increasingly complex projects autonomously — but always under human oversight.
- Security standards for AI-generated code will emerge as their own discipline. Companies that invest early gain a competitive edge.
- Quality gaps between providers will widen: Those who use AI correctly deliver faster and better. Those who misuse it as a shortcut produce technical debt.
Conclusion: Seize Opportunities, Know the Risks
AI in software development isn’t a trend that will fade away. GPT-5.3 Codex and Claude Opus 4.6 impressively demonstrate what’s possible — and equally clearly show where the limits lie. For small and medium-sized businesses, real opportunities are opening up: faster delivery, lower costs, higher quality — provided that human expertise remains the foundation.
The question for your business isn’t whether to adopt AI-assisted development — but with whom and how well secured.
Frequently Asked Questions (FAQ)
Will AI completely replace software developers?
No. AI agents dramatically accelerate implementation, but conception, architectural decisions, security audits, and quality assurance still require human expertise. Developers are becoming “AI managers” — they direct and verify what AI produces.
What’s the difference between ChatGPT Codex and Claude Opus for my project?
GPT-5.3 Codex excels in speed and platform integration — ideal for rapid prototyping and standardized tasks. Claude Opus 4.6 offers deeper understanding and a massive context window — ideal for complex projects with large codebases. In practice, professional teams often use both models complementarily.
Is AI-generated code secure?
Not automatically. AI-generated code can contain security vulnerabilities and should undergo the same review processes as manually written code. Professional code reviews and security audits remain indispensable — especially when an AI agent wrote the code.
What does AI-assisted software development cost?
API costs vary: GPT-5.3 Codex charges from $1.50 per million input tokens, Claude Opus 4.6 from $5.00 per million. More important than model costs, however, are conception, security review, and quality assurance — that’s where the real value of professional service providers lies.
Want to integrate AI into your software projects the right way?
We advise small and medium-sized businesses in the Cologne area on the opportunities and limitations of AI-assisted web development and AI automation. Transparent, technically sound, and without empty promises.